In this tutorial we use a catboost, one of the best library for a gradient boosting on trees.
You can install catboost with pip:
pip install catboost
or with conda:
conda install -c conda-forge catboost
[3]:
import catboost
from catboost import *
import shap
shap.initjs()

Let’s first explore shap values for dataset with numeric features
[4]:
X,y = shap.datasets.boston()
[5]:
model = CatBoostRegressor(iterations=300, learning_rate=0.1, random_seed=123)
model.fit(X, y, verbose=False, plot=False)
[5]:
<catboost.core.CatBoostRegressor at 0x1a216c5160>
[6]:
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X)
# visualize the first prediction's explanation
shap.force_plot(explainer.expected_value, shap_values[0,:], X.iloc[0,:])
[6]:
Have you run `initjs()` in this notebook? If this notebook was from another user you must also trust this notebook (File -> Trust notebook). If you are viewing this notebook on github the Javascript has been stripped for security. If you are using JupyterLab this error is because a JupyterLab extension has not yet been written.
The above explanation shows features each contributing to push the model output from the base value (the average model output over the training dataset we passed) to the model output. Features pushing the prediction higher are shown in red, those pushing the prediction lower are in blue.
If we take many explanations such as the one shown above, rotate them 90 degrees, and then stack them horizontally, we can see explanations for an entire dataset (in the notebook this plot is interactive):
[8]:
# visualize the training set predictions
shap.force_plot(explainer.expected_value, shap_values, X)
[8]:
Have you run `initjs()` in this notebook? If this notebook was from another user you must also trust this notebook (File -> Trust notebook). If you are viewing this notebook on github the Javascript has been stripped for security. If you are using JupyterLab this error is because a JupyterLab extension has not yet been written.
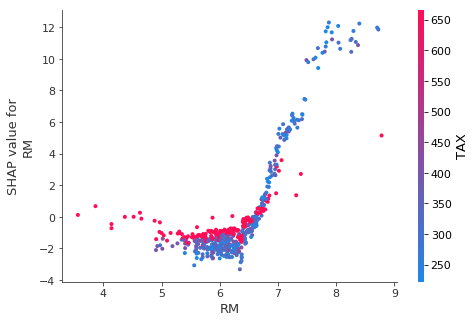
To understand how a single feature effects the output of the model we can plot the SHAP value of that feature vs. the value of the feature for all the examples in a dataset. Since SHAP values represent a feature’s responsibility for a change in the model output, the plot below represents the change in predicted house price as RM (the average number of rooms per house in an area) changes. Vertical dispersion at a single value of RM represents interaction effects with other features. To help reveal these interactions dependence_plot automatically selects another feature for coloring. In this case coloring by RAD (index of accessibility to radial highways) highlights that RM has less impact on home price for areas close to radial highways.
[9]:
# create a SHAP dependence plot to show the effect of a single feature across the whole dataset
shap.dependence_plot("RM", shap_values, X)
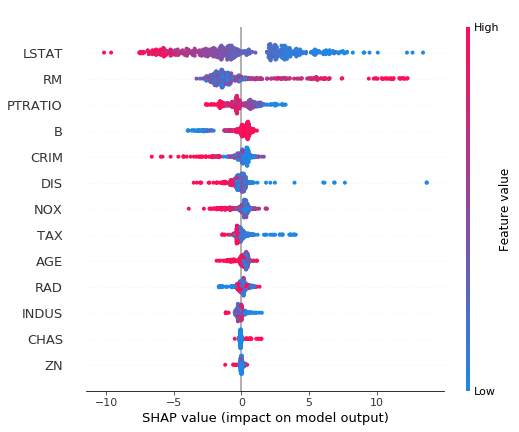
To get an overview of which features are most important for a model we can plot the SHAP values of every feature for every sample. The plot below sorts features by the sum of SHAP value magnitudes over all samples, and uses SHAP values to show the distribution of the impacts each feature has on the model output. The color represents the feature value (red high, blue low). This reveals for example that a high LSTAT (% lower status of the population) lowers the predicted home price.
[11]:
# summarize the effects of all the features
shap.summary_plot(shap_values, X)
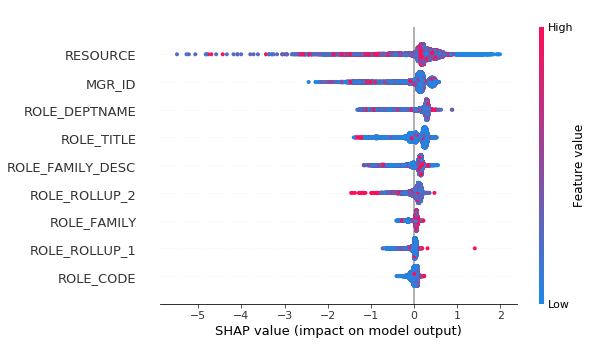
You can also use shap values to analyze importance of categorical features
[12]:
from catboost.datasets import *
train_df, test_df = catboost.datasets.amazon()
y = train_df.ACTION
X = train_df.drop('ACTION', axis=1)
cat_features = list(range(0, X.shape[1]))
[13]:
model = CatBoostClassifier(iterations=300, learning_rate=0.1, random_seed=12)
model.fit(X, y, cat_features=cat_features, verbose=False, plot=False)
[13]:
<catboost.core.CatBoostClassifier at 0x10925d198>
[14]:
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(Pool(X, y, cat_features=cat_features))
The model has complex ctrs, so the SHAP values will be calculated approximately.
Here is the visualization of feature importances for one positive and one negative example. Note, that binary classification output is a value not in range [0,1]. You need to calculate a sigmoid function value, to calculate final probabilities.
[15]:
test_objects = [X.iloc[0:1], X.iloc[91:92]]
for obj in test_objects:
print('Probability of class 1 = {:.4f}'.format(model.predict_proba(obj)[0][1]))
print('Formula raw prediction = {:.4f}'.format(model.predict(obj, prediction_type='RawFormulaVal')[0]))
print('\n')
Probability of class 1 = 0.9964
Formula raw prediction = 5.6094
Probability of class 1 = 0.0301
Formula raw prediction = -3.4734
[16]:
shap.force_plot(explainer.expected_value, shap_values[0,:], X.iloc[0,:])
[16]:
Have you run `initjs()` in this notebook? If this notebook was from another user you must also trust this notebook (File -> Trust notebook). If you are viewing this notebook on github the Javascript has been stripped for security. If you are using JupyterLab this error is because a JupyterLab extension has not yet been written.
[17]:
shap.force_plot(explainer.expected_value, shap_values[91,:], X.iloc[91,:])
[17]:
Have you run `initjs()` in this notebook? If this notebook was from another user you must also trust this notebook (File -> Trust notebook). If you are viewing this notebook on github the Javascript has been stripped for security. If you are using JupyterLab this error is because a JupyterLab extension has not yet been written.
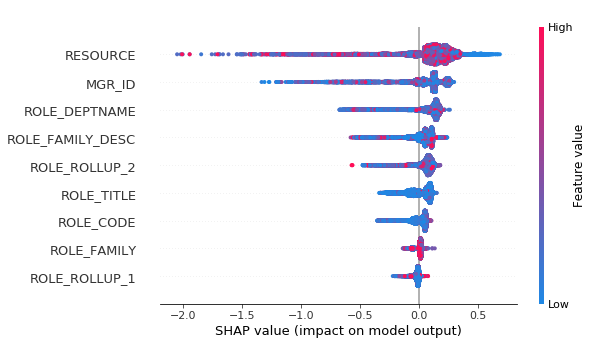
In the summary plot below you can see that absolute values of the features don’t matter, because it’s hashes. But it is clear from the plot what is the effect of different features.
[19]:
shap.summary_plot(shap_values, X)
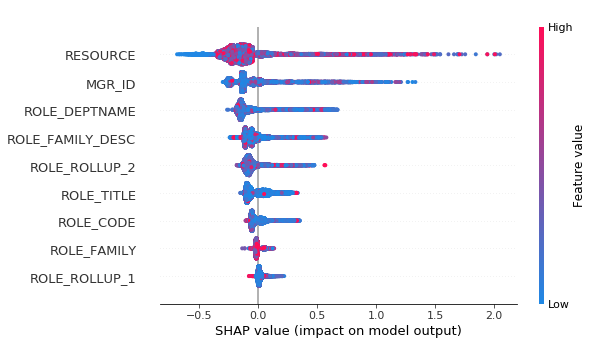
You can calculate shap values for multiclass.
[20]:
model = CatBoostClassifier(loss_function = 'MultiClass', iterations=300, learning_rate=0.1, random_seed=123)
model.fit(X, y, cat_features=cat_features, verbose=False, plot=False)
[20]:
<catboost.core.CatBoostClassifier at 0x1a23063908>
[21]:
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(Pool(X, y, cat_features=cat_features))
The model has complex ctrs, so the SHAP values will be calculated approximately.
Summary plot of SHAP values for formula raw predictions for class 0.
[22]:
shap.summary_plot(shap_values[0], X)
And force plot for class 1.
[23]:
shap.summary_plot(shap_values[1], X)
[ ]: